Data
Data 톺아보기
Data는 무엇일까?
데이터는 왜 중요할까?
데이터가 우리에게 말하고자 하는 바는 무엇일까?
Data-driven은 또 무엇일까?
그냥 순수한 호기심/궁금증에서 시작해서 알게 된 것들을 정리하고 공유하고자 한다.
다루는 김에 간단하지만 재밌는 역사적 에피소드들도 함께 다룰 예정이다.

☾ Table of contents
☺︎ 君の名は, データ
- DIKW pyramid
- Find the hidden data
☺︎ Useful data
☺︎ Data driven?
☻ Reference
☺︎ 君の名は, データ
너의 이름은, 데이터.
데이터란?
What we call data are observations of real-world phenomena. [1]
말 그대로 우리가 관측하는 모든 것을 데이터라고 한다. 여기서 설명한 예시를 좀 더 살펴 본다면 아래와 같다.
For instance, stock market data might involve observation of daily stock prices, announcements of earnings by individual companies, and even opinion articles from pundits. Personal biometric data include measurements of our minute-by-minute heart rate, blood sugar level, blood pressure, etc. Customer intelligence data includes observations such as “Alice bought two books on Sunday,”, “Bob browsed there pages on the website,” and “Charlie clicked on the special offer link from last week.” We can come up with endless examples of data across different domains. [1]
개인적으로 여기서 적어놓은 것이 내가 생각하기에는 The most ideal definition of data 라고 생각한다. 위에서 언급했듯이 도메인에 따라서 데이터에 대한 예는 수도 없다.
여기서 재밌는 사실은 관측된 모든 것들이 데이터가 되고, 우리도 결국은 어떠한 도메인에서 데이터가 된다는 것이다.
이 얘기를 처음 들었던 것은 미국에서 Geophysics 데이터 분석을 하고 있을 때 였다. “데이터가 뭐예요?” 라는 내 질문에 로버트가 “쉽게 생각해서 관측되는 모든 것. 모든것이 데이터가 될수 있어.”라고 말해주었다. 사실 그때는 이게 무슨 말인지 도통 이해가 되지 않았는데 이제는 좀 이해할 것 같다.
너무 재밌지 않은가? 우리는 데이터를 분석하는 주체이자 데이터 자체이기도 하다.

좀 더 살펴봐서 wikipedia에서 설명한 데이터의 의미는 아래와 같다.
These are some of the different types of data. Data are individual facts, statistics, or items of information, often numeric. In a more technical sense, data are a set of values of qualitative or quantitative variables about one or more persons or objects, while a datum (singular of data) is a single value of a single variable. [2]
데이터는 사실, 통계, 또는 정보를 나타낸다. 기술적인 의미에서 데이터는 질적 혹은 양적 변수이다.
☻ DIKW pyramid
그러면 이러한 데이터는 중요한지 알아보도록 하자.
우선, 이를 위해서 DIKW (Data Information Knowledge Wisdom) Pyramid 즉 지식 피라미드에 대해서 알아야 한다.
DIKW 피라미드란, Data, Information, Knowledge, Wisdom으로 이루어진 계층도로 문헌 정보관리, 정보 시스템, 지식 관리 영역에서 흔히 인용된다. [3]
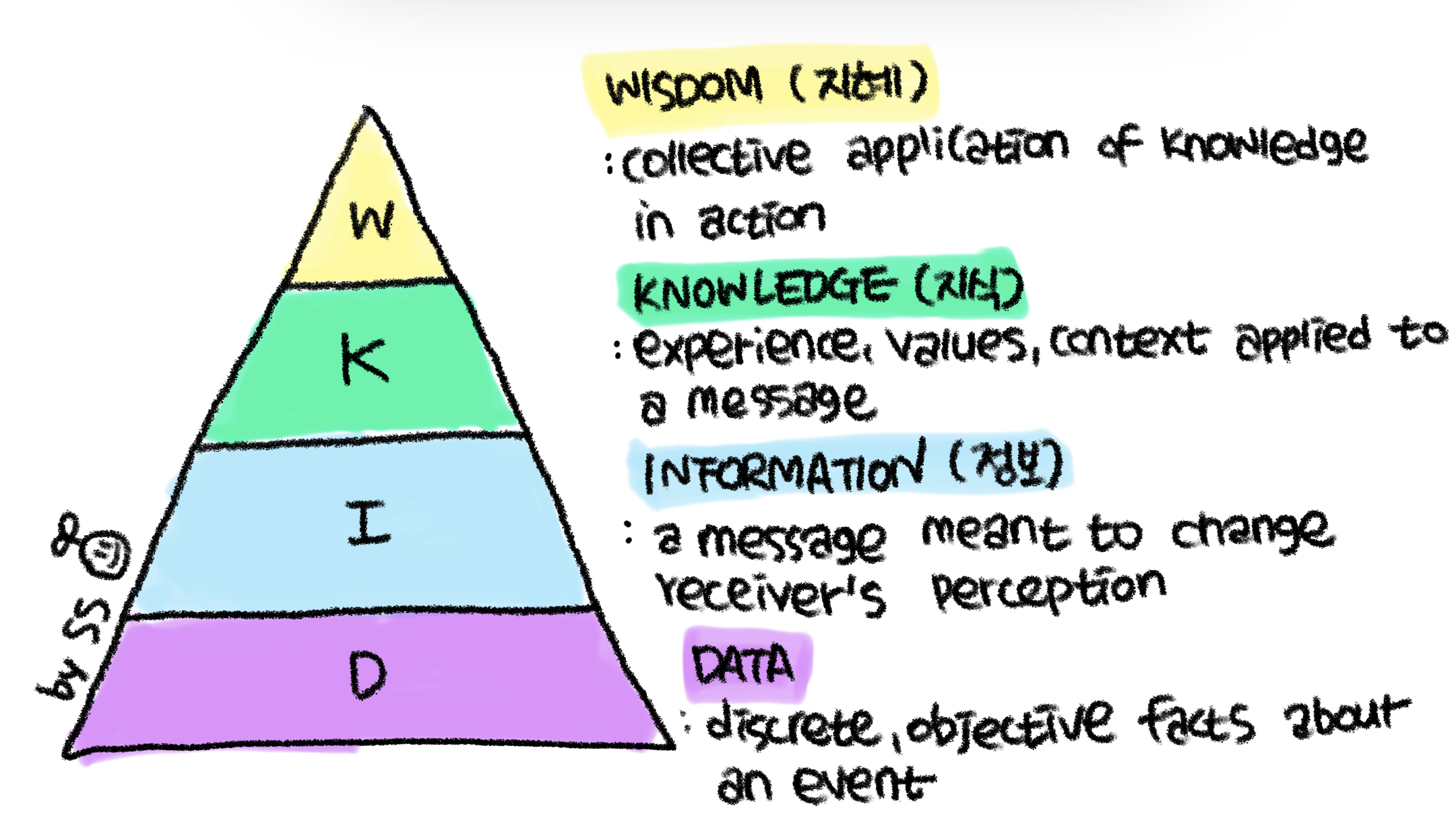
여기서 데이터는 앞에서 설명했듯 관찰, 측정을 통해서 수집된 사실이나 값, 수치, 문자 등 가공되지 않은 원본 데이터로 객관적 사실을 의미 한다.
이러한 데이터는 그 자체로 의미를 가지기 어렵다. 따라서 이러한 데이터가 가치를 갖기 위해서는 우리가 필요한 정보를 추출하고 처리하는 과정이 필요하다. [2,4]
Data, information, knowledge, and wisdom are closely related concepts, but each has its role concerning the other, and each term has its meaning. According to a common view, data are collected and analyzed; data only becomes information suitable for making decisions once it has been analyzed in some fashion. One can say that the extent to which a set of data is informative to someone depends on the extent to which it is unexpected by that person. The amount of information contained in a data stream may be characterized by its Shannon entropy.
이렇게 Data에서 필요한 것들만 골라지면 Information이 되고, 나아가 Knowledge, Wisdom이 된다. [4]
-
자료(Data)란 관찰, 측정을 통해서 수집된 사실이나 값, 수치, 문자 등을 의미합니다. 지식 피라미드에서 데이터가 갖는 중요한 특징은 ‘가공되지 않았다’는 사실이다. 가공되지 않은 데이터는 그 자체로는 의미를 지니기 어렵다.
-
정보(Information)는 여러 가지 데이터 중에 사용자에게 ‘필요한’ 데이터이다. 데이터 중에 사용자의 필요에 따라 정제되거나 가공된 데이터를 정보라고 부른다.
-
지식(Knowledge)은 정보를 일반화하고 체계화하여 바로 적용·활용할 수 있도록 만든 것을 의미한다. 서로 연결된 정보들의 패턴을 바탕으로 예측한 결과물을 지식이라고 볼 수 있다.
-
지혜(Wisdom)는 지식에 유연성을 더하고, 상황과 맥락에 맞는 규칙을 적용하는 것을 의미한다. 즉, 지혜는 근본적인 원리에 대한 깊은 이해를 바탕으로 하는 창의적 아이디어이다.
사람들은 AI가 궁극적으로 추구하는 바는 Wisdom (지혜)의 영역이라고 한다. 따라서 좋은 데이터가 중요하고, 거기서 정보와 지식을 얻고 최종적으로는 Wisdom (지혜) 혹은 insight를 얻는 것이 중요하다. [4]
그렇다면 어떤 데이터가 중요하고 필요한 데이터인지 판단하는 것이 중요한데. 이는 뒤의 ☺︎ Useful data 에서 좀 더 자세하게 다루고자 한다.
잠시 다른 얘기지만, 영국의 시인 T. S. Eliot을 인용하면 DIKW 피라미드의 중요성을 다시 한번 알 수 있다. [5]
Where is the wisdom we have lost in knowledge? Where is the knowledge we have lost in information?
그럼 이러한 Data가 Information이 되고, Knowledge가 된 예들을 잠시 살펴보자.
☻ Find the hidden data
데이터는 실제 많은 영역에서 사용되어 왔으며, 실제 Information(정보)와 Knowledge(지식)을 얻는데 사용되어 왔다.
여기 아주 재미있는 역사적 이야기가 있다.
우리가 아주 많~이 사용하고 있는 데카르트 좌표계는 사실 파리를 통해서 알게 되었다. [6]
즉, 파리의 이동을 관측하고 그 데이터를 기반으로 만들어졌다는 의미이다.

프랑스 수학자 르네 데카르트는 늦게까지 침대에 누워있는 것을 좋아했다. 어느날 침대에 누워서 천장을 보는데 파리 한마리가 날라다니고 있었다.
그때, 그는 ‘저 파리의 위치를 나타낼수 있는 좋은 방법이 뭐가 있을까? 아하~ 천장의 저 코너를 기준점으로 잡고, 그 점을 기준으로 파리의 위치를 나타내보자’라고 해서 좌표계가 만들어졌다.
The coordinate system we commonly use is called the Cartesian system, after the French mathematician René Descartes (1596-1650), who developed it in the 17th century. Legend has it that Descartes, who liked to stay in bed until late, was watching a fly on the ceiling from his bed. He wondered how to best describe the fly’s location and decided that one of the corners of the ceiling could be used as a reference point. [6]
흠..그렇다. 나라면 에프킬라로 파리를 죽일 생각을 했을텐데 그는 프랑스인답게 여유롭게 파리를 보며 좌표계를 생각해냈다. 역시 French!

아무튼, 여기서 우리가 관심을 갖아야 할 부분은 좌표계를 생각해낸 부분이 아닌 파리이동의 관측이다.
파리가 날아다니면서 다른 위치에 앉아 있던 것 자체가 데카르트의 관측(Observation)된 사실이고 곧 데이터이다. 이를 통해 정보(Information)과 지식(Knowledge)를 얻어 좌표계를 만든 것이다.
수학이나 물리학에서 데이터를 기반으로 이론을 성립한 바는 수도 없이 많다.
너무나 유명한 뉴턴의 만유인력의 법칙 도 사과가 떨어지는 것을 관측하고 정립하였고, 갈릴레오의 낙하실험 은 피사의 사탑에서 서로 다른 무게의 물체를 떨어트린 실험/관측한 결과이다. 또한 넘치는 목욕물을 관측한 후 유레카를 외쳐서 유명해진 Archimedes’ principle (부력) 등이 있다.
이러한 것들도 관측된 데이터를 기반으로 하고 있다.
즉, 관측된 데이터를 기반으로 패턴과 현상(Phenomena)를 이해하고, 여기에 constraints, assumption, and conditions등을 고려해서 수학적/물리학적 식과 이론을 정립한거라고 생각한다.
따라서 실제 데이터는 더 많은 정보를 포함하고 있고, 요즘 우리가 많이 사용하는 Data-driven은 꽤 중요하다고 생각한다.
☺︎ Useful data
그럼 유용한 필요한 데이터라는 어떤 것일까?
사실 데이터는 상황에 따라 유용할수도 있고 유용하지 않을 수도 있다.
Information is considered more reliable than data. It helps the researcher to conduct a proper analysis. The data collected by the researcher, may or may not be useful. Information is useful and valuable as it is readily available to the researcher for use. [7]
물론 손상된 데이터들 (damaged or spoiled data)의 경우는 명백하게 유용하지 않다고 말할 수도 있지만, 이러한 예외를 제외하고는 우리가 풀고자 하는 문제에 따라 중요도가 달라질수도 있다고 생각한다.
예로 noisy data라 여겨져서 pre-processing(전처리) 과정에서 filtering(필터링)을 통해 제거했는데, 다른 문제에서는 꽤 중요한 정보를 제공하는 경우가 있다.
여기서 말하는 noisy data란 신호 대 잡음비 (Signal-to-noise ratio,SNR)가 낮은 데이터이다. 이는 무의미한 추가 정보가 많은 데이터로 데이터 분석 성능에 부정적인 영향을 끼치고, 방해의 요소가 되어서 제거하기도 한다. [8]
자세한 내용은 아래 wikipedia의 definition을 참고하도록 한다.
Noisy data are data that is corrupted, or distorted, or has a low signal-to-noise ratio. Improper procedures (or improperly-documented procedures) to subtract out the noise in data can lead to a false sense of accuracy or false conclusions. Data = true signal + noise Noisy data are data with a large amount of additional meaningless information in it called noise.[1] This includes data corruption and the term is often used as a synonym for corrupt data. It also includes any data that a user system cannot understand and interpret correctly. Many systems, for example, cannot use unstructured text. Noisy data can adversely affect the results of any data analysis and skew conclusions if not handled properly. Statistical analysis is sometimes used to weed the noise out of noisy data.
(여기서는 noisy data와 noise를 동일한 의미로 사용하기로 한다.)
이와 관련해서 예전에 seismology 업무 진행시 겪었던 경험을 예로 들어보기로 한다.
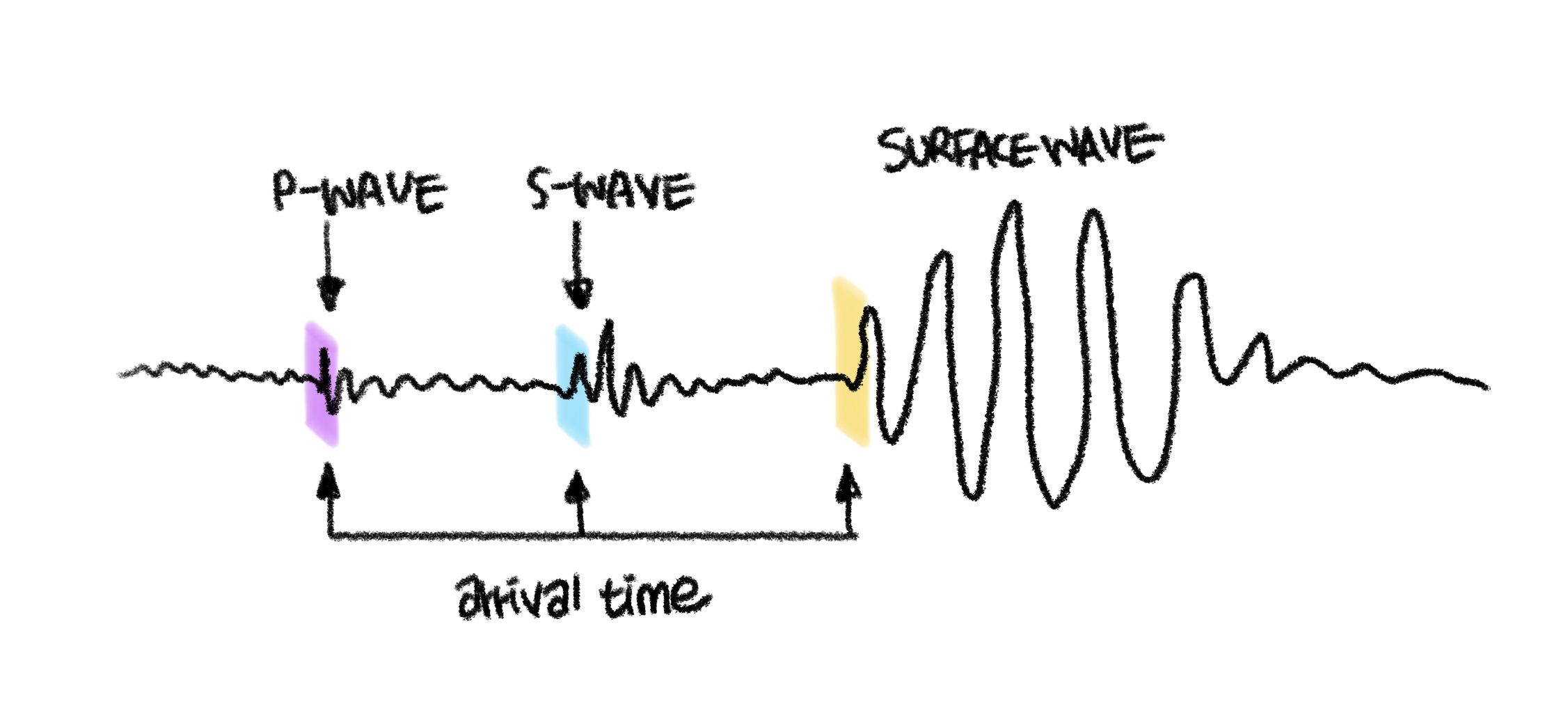
사실 지진 데이터 분석시 가장 많이 거론되는 문제는 earthquake arriving time picking 혹은 earthquake prediction/detection 이다.
지진의 도착시간 혹은 지진의 발생 시점을 예측해서 막대한 인명피해를 줄이는 것이 중요하다.
따라서 Body wave (p-wave or S-wave)가 중요한 데이터이다.
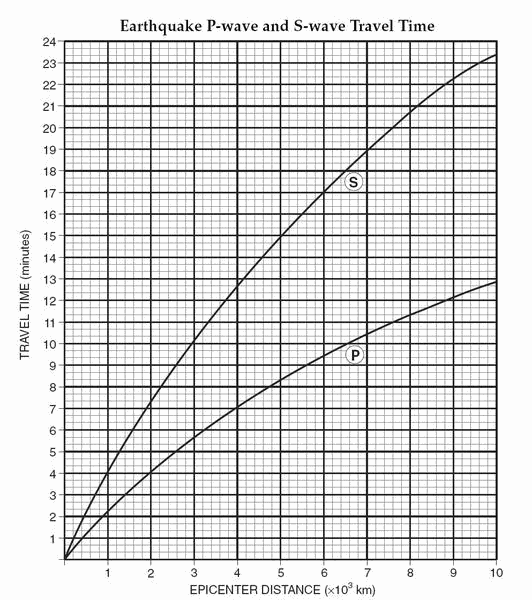
Body wave는 진앙(epicenter)으로부터의 거리를 구하거나, 지진의 도착 시간들을 예측하거나 할 때 사용된다. 반면에 여러가지 sources에서 발생하는 noise의 경우, 우리가 확인하고자 하는 Body wave에 섞여 있어서 분석에 방해가 되고 따라서 제거 요인이 된다.
따라서 이러한 경우 Body wave는 정보를 제공해주는 유용한 데이터 로 볼 수 있지만, noise 들은 우리가 pre-processing (전처리)에서 걸러내야하는 불필요한 데이터이자 정보 로 볼 수 있다.
그런데, 여기 재밌는 연구가 있다. 실제 연속적으로 기록된 지진파에서 random noise와 not random noise를 구분하는 방법을 개발한 논문이다. [9]
We develop a methodology to separate continuous seismic waveforms into random noise (RN), not random noise (NRN) produced by earthquakes, wind, traffic and other sources of ground motions, and an undetermined mixture of signals.
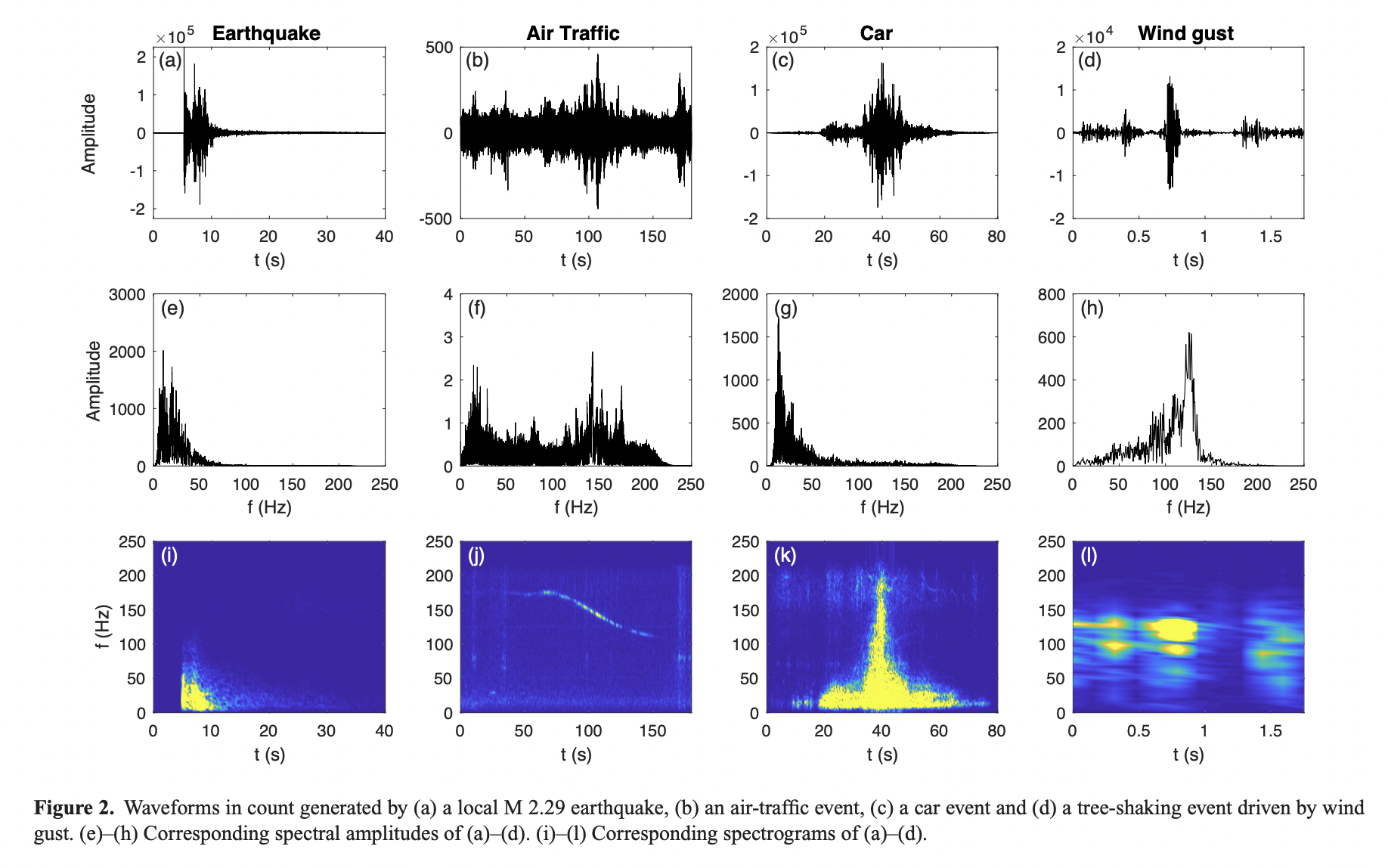
4개의 서로 다른 sources의 signal에 대한 waveforms과 spectrogram을 보면 noise도 비행기나 헬기 (air traffic), 자동차 (car), 혹은 바람 (wind gust)등에서 발생하는 파로 나눠진다.
특히 spectrogram (맨 마지막 줄에 있는 그림)을 보면 각각 모두 다른 형태를 띄고 있다.
재밌는 것은 비행기의 경우 실제 Doppler effect로 인해 frequency (주파수)가 감소하는 것이 보인다.
이 논문에서는 random noise인지 not random noise인지를 구분을 위한 방법론 개발이 목표이고, 따라서 noise가 중요한 정보이자 데이터로 취급된다.
이때는 body wave는 제거하고 순수하게 noise만을 분석하였다.
이러한 예시를 기반으로 여기서 전달하고자 하는 메세지는 분석하고자 하는 대상, 풀고자 하는 문제, 데이터 사이언티스/분석가의 의도에 따라서 유용한 데이터가 되기도 하고 불필요한 데이터가 되기도 한다는 것이다.
☺︎ Data-driven?
마지막으로 요즘 많이 사용되고 있는 Data-driven에 대해서 가볍게 다루고자 한다.
Data-driven의 정의에 대해서 wikipedia를 확인해보면 [10]
The adjective data-driven means that progress in an activity is compelled by data, rather than by intuition or by personal experience.
개인의 경험이나 직관이 아닌 데이터에 의해서 만들어지는 것 을 의미한다.
또다른 정의를 보면 Data-driven이란 데이터 분석 및 해석을 기반으로 전략적 결정을 내림 라고 한다. [11]
When a company employs a “data-driven” approach, it means it makes strategic decisions based on data analysis and interpretation. A data-driven approach enables companies to examine and organise their data with the goal of better serving their customers and consumers. By using data to drive its actions, an organisation can contextualise and/or personalise its messaging to its prospects and customers for a more customer-centric approach.
정리하면 데이터 즉 관측된 것에서 정보를 얻고, 이를 기반으로 지식과 지혜 (혹은 insight라고 봐도 무방할 것 같다)로 발전 시킨다고 볼 수 있고, 이는 앞에서 언급하였던 DIKW pyramid와 일맥상통 한다.
데이터는 정말 중요하다.
하지만 여기서 한가지 당부의 말씀을 드리자면 데이터 분석시 데이터를 잘 이해하는 것도 중요하지만 Domian Knowledge를 갖는 것도 중요하다고 생각한다.
나또한 처음 seismology 데이터 분석을 시작했을때 Geophysics/seismology 책을 찾아보고 많은 seismologists들에게 질문하면서 각각의 데이터들이 갖은 의미들을 이해하려 노력했다.
추후에 데이터 분석 및 모델링에 대한 글도 작성해보려 한다.

끝으로 데이터는 무척 재밌는 것 같다. 데이터 하나 하나가 과거, 현재, 미래의 인과관계를 보여준다고 생각한다.
뭔가 damaged or spoiled data 혹은 noise에도 다 이유가 있다. 그러한 이유를 이해하고 잘 처리해주는 것도 우리의 몫이라고 생각한다.
☻ Reference
- Book: Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists
- wikipedia: data
- DIKW 피라미드
- AI4SCHOOL: Part 2. 지식 피라미드 (DIWK 피라미드)
- TS Eliot and the Pyramid of Organisational Knowledge
- René Descartes and the Fly on the Ceiling
- Difference between Information and Data
- wikipedia: noisy data
- Paper : Detection of random noise and anatomy of continuous seismic waveforms in dense array data near Anza California
- wikipedia: Data-drive
- Data-driven
☻ image sources
모두의 연구소에서 진행하는 “함께 콘텐츠를 제작하는 콘텐츠 크리에이터 모임”인 COCRE(코크리) 의 2기 회원으로 제작한 글입니다