data2vec
[Review | 논문리뷰] data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
🔠 code
☾ Table of contents
☺︎ What the data2vec is.
☺︎ Related work
- Self-supervised learning in CV, NLP, and speech
- Multimodal pre-training
☺︎ Method
- Model architecture
- Masking
- Trainning targets
☺︎ Experimental setup + Results
- Computer vision
- Speech processing
- Natural language processing (NLP)
- Ablations
☺︎ Discussion
- Modality specific features extractors and masking
- Structured and contextualized targets
- Representation collapse
☺︎ Extra notion
☻ Reference
☺︎ What the data2vec is [1-4].

Data2vec은 쉽게 말해서 speech, NLP 또는 computer vision에 등에 동일한 learning method를 사용하는 것이다.
기존 방법들은 Modality-specific targets (words, visual tokens or units of human speech)을 예측하였지만 이와 다르게, data2vec은 contextualized latent representations을 예측한다. 그리고 이러한 contextualized latent representations는 entire input으로부터의 정보를 포함하고 있다.
또한 여기서는 distillation setup, 즉 student-teacher network를 기반으로 하고 있고, 둘 다 같은 구조의 standard transformaer architecture을 사용한다.
teacher model은 original data를 입력하여 representation을 생성하고 이는 target 이 된다. 그리고 student model은 original data에 masking을 한 masked data를 입력하여 original input의 representation을 예측한다. 그 후 teacher model은 다시 student model의 가중치를 복사하여 최신상태를 유지합니다.
☻ self-supervised learning [3]
supervised learning의 경우, labeled dataset을 사용하여 학습을 시킨다. 하지만 이러한 labeled data의 경우 비싸고, 또한 대용량 데이터를 구하기가 어렵다. 따라서 자체적으로 label을 만들어서 학습을 시키자고 제안된 방법이 self-supervised learning이다.
좀 더 details하게 확인하면 [5,6]
Self-supervised learning (SSL) is a method of machine learning. It learns from unlabeled sample data. It can be regarded as an intermediate form between supervised and unsupervised learning. It is based on an artificial neural network. The neural network learns in two steps. First, the task is solved based on pseudo-labels which help to initialize the network weights. Second, the actual task is performed with supervised or unsupervised learning.
이러한 self-supervised learning은 CV, NLP, Speech에 사용된 경우를 확인해보면,
CV의 경우는 크게 Rotation과 Context prediction이 있다 [3,7,8].
우선, rotation 시킨후 CNN에 넣어서 회전을 맞추는 task를 푸는 것이다. 이런 경우, 동일한 이미지가 들어오는데 각도가 바뀌는 것이다.
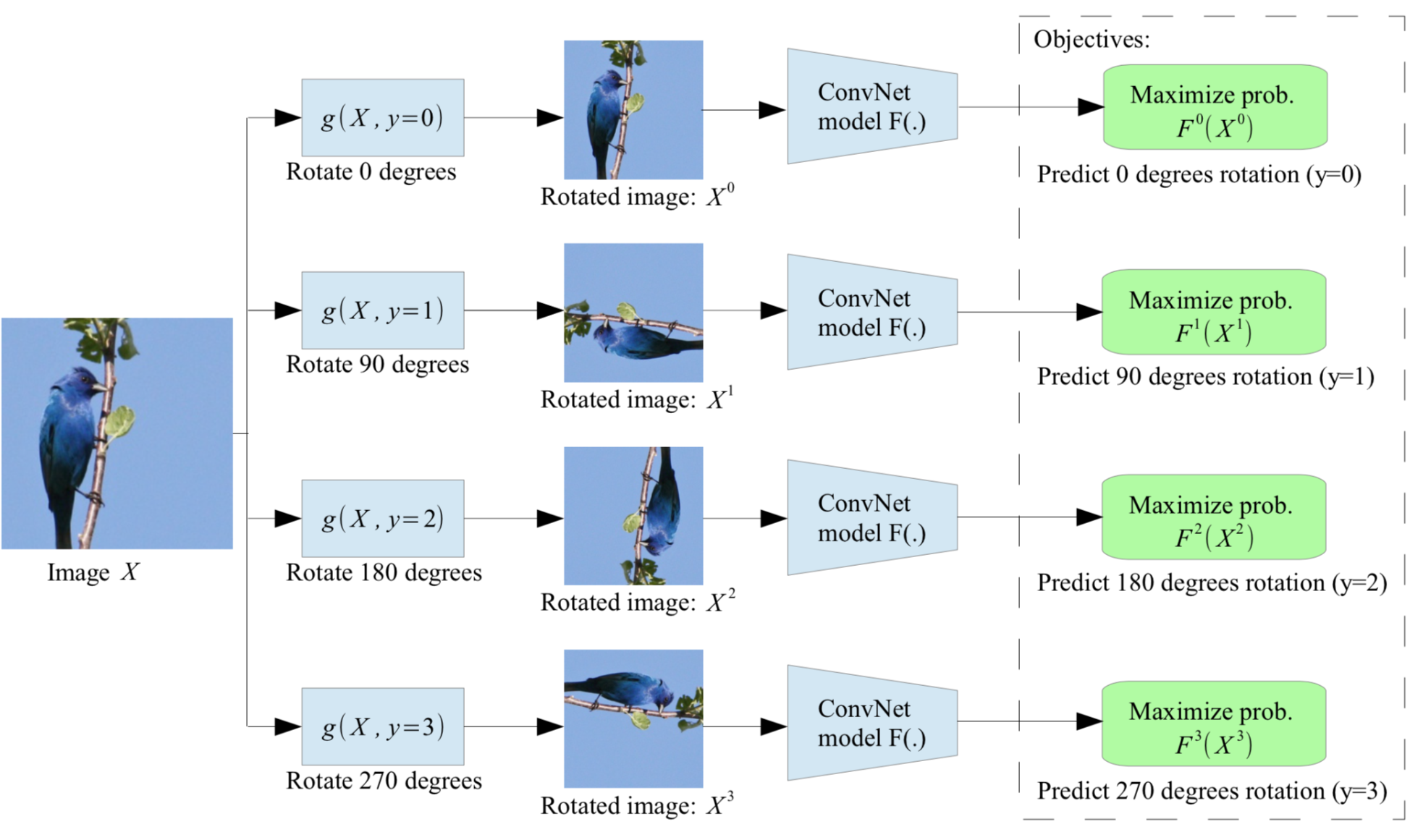
Fig [7]
Context prediction의 경우는 patch 생성하고, 가운데 이미지를 앵커처럼 사용하고 나머지 8개 이미지중 랜덤하게 이미지를 갖고와서 두 이미지를 CNN에 넣어서 앵커 제외하고 갖고온 query 이미지가 몇번째 이미지인지 맞춰주는 task이다. 여기서 더 나아간 것이 두개의 이미지가 아닌 총 9개의 이미지를 모두 사용해서 CNN에 넣은 후 원래 이미지의 위치를 찾아내는 것으로 jigsaw puzzle라고 불리운다.
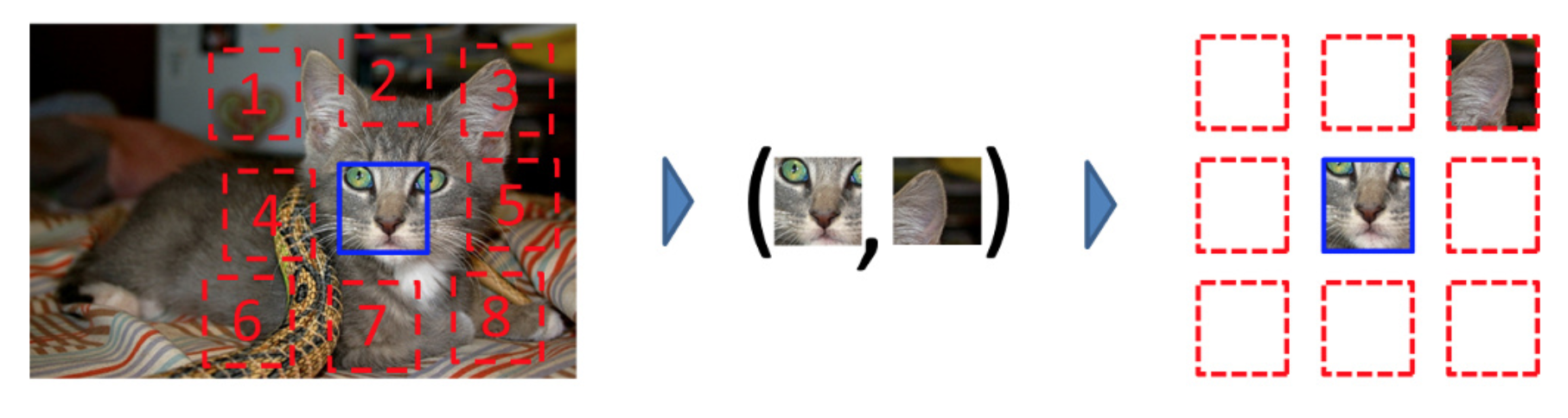
Fig [8]
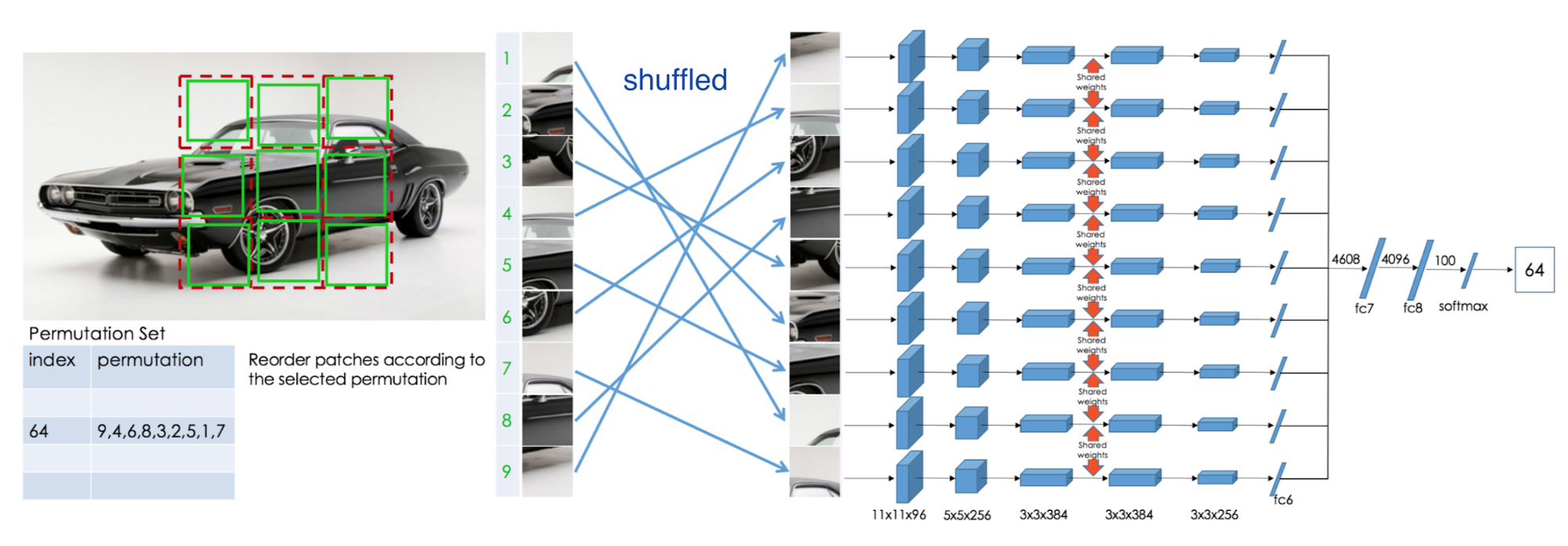
Fig [7]
NLP의 경우는 BERT
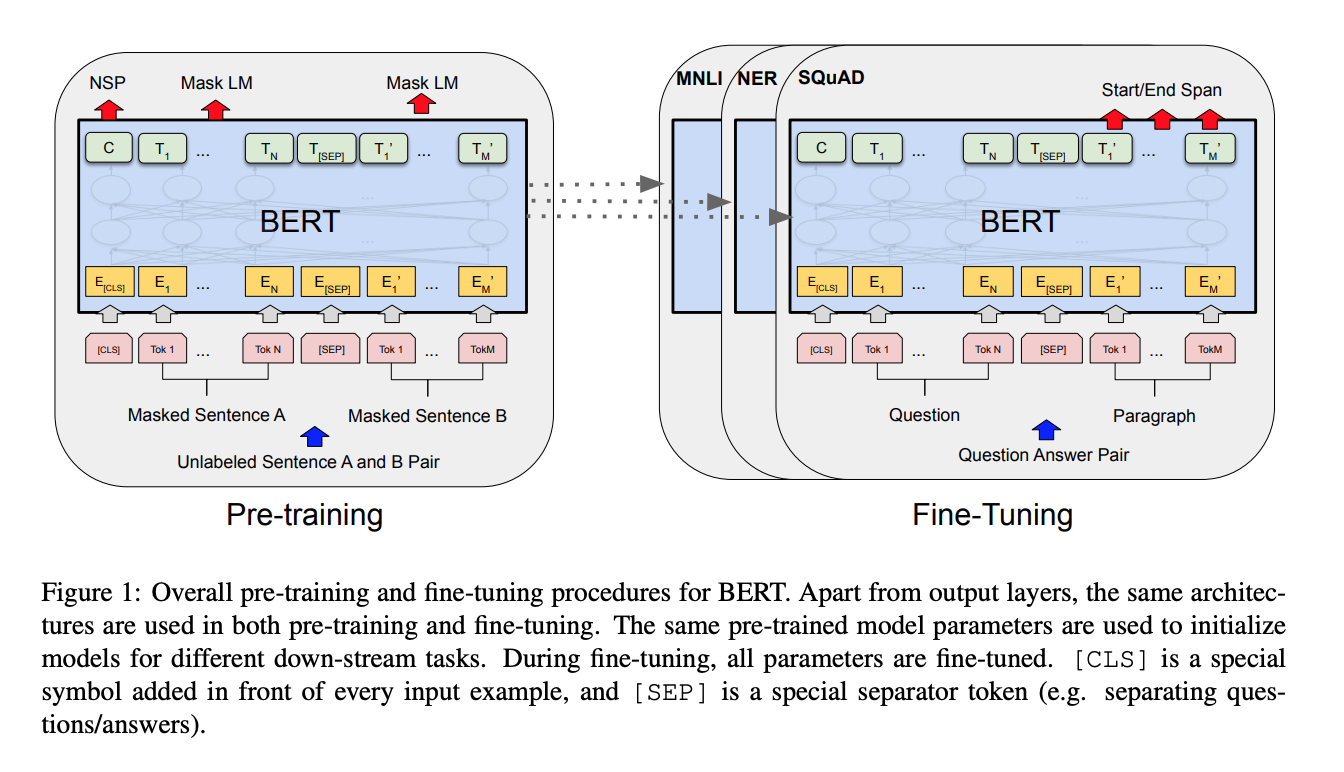
Fig [9]
speech의 경우는 wave2vec 2.0이 대표적인 예이다 [1].
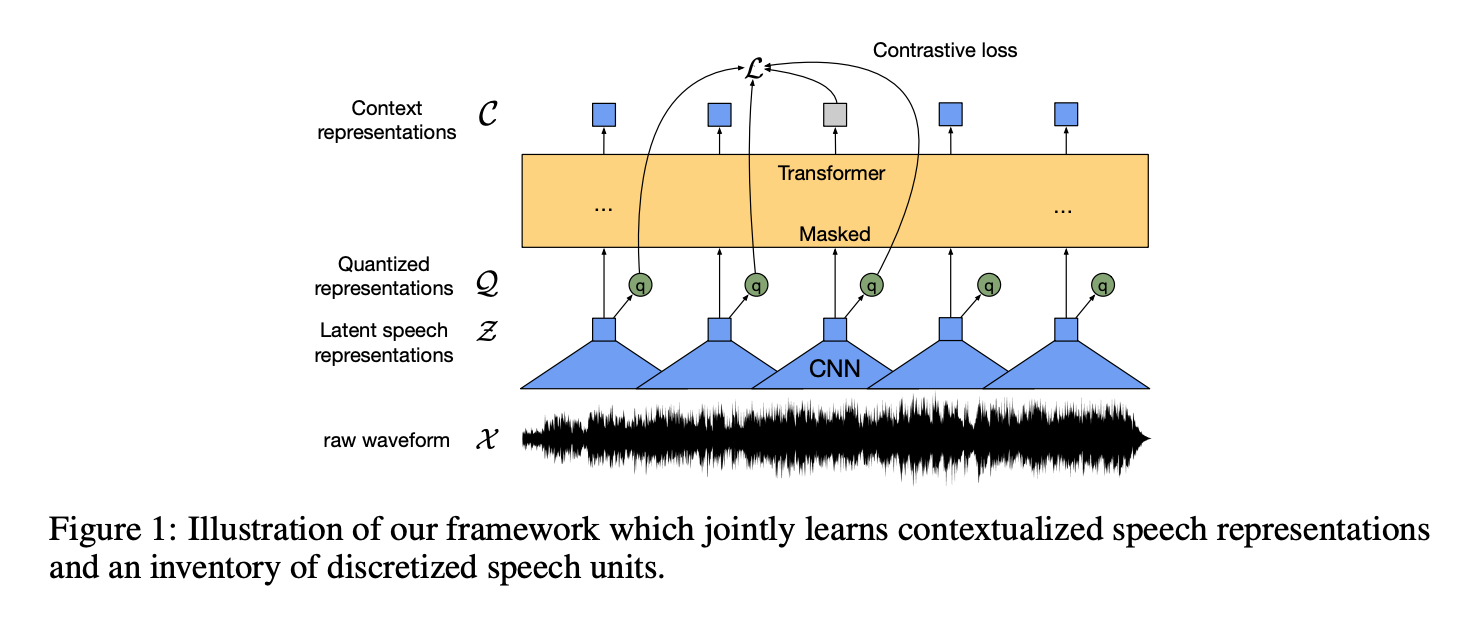
Fig [10]
이를 통해 각각의 modality에서 서로 다른 방법론을 각기 적용해서 self-supervised learning을 진행해 왔다는 것을 확인 할 수 있었다.
☻ Multimodal pre-training
Multimodality라는 것의 정의를 보면 [11]
The term multimodality refers to the combination of multiple sensory and communicative modes, such as sight, sound, print, images, video, music, and so on, that produce meaning in any given message.
좀 더 자세히 살펴보면 [12] (여기서 multimodality와 multimodal은 동일하다.)
여러가지 형태와 의미로 컴퓨터와 대화하는 환경으로 모달 (modality)란 인터랙션 과정에서 사용되는 의사소통 채널을 가르킨다. 멀티모달은 텍스트, 음성, 이미지, 영상등 서로 다른 양식의 데이터를 자유자재로 이해하고 변환할 수 있어 사람처럼 배우고 생각하며 추론할 수 있다.
이러한 멀티모달의 경우 cross-modal representation을 생성을 목적으로 사용될 수 있다 [1].
There has been a considerable body of research on learning representations of multiple modalities simultaneously often using paired data (Aytar et al., 2017; Radford et al., 2021b; Wang et al., 2021; Singh et al., 2021) with the aim to produce cross-modal representations which can perform well on multi-modal tasks and with modalities benefiting from each other through joint training (Alayrac et al., 2020; Akbari et al., 2021) with recent methods exploring few-shot learning (Tsimpoukelli et al., 2021). Our work does not perform multimodal training but aims to unifiy the learning objective for self-supervised learning in different modalities. We hope that this will en- able better multimodal representations in the future.
본 연구에서는 Modality가 다르더라도 동일한 방식으로 self-supervised learning을 할 수 있는 방법론을 제안하였다. 이는 modality가 달라서 다른 input이 들어와도 동일한 형태의 contextualized representations를 예측할 수 있다.
☺︎ Method
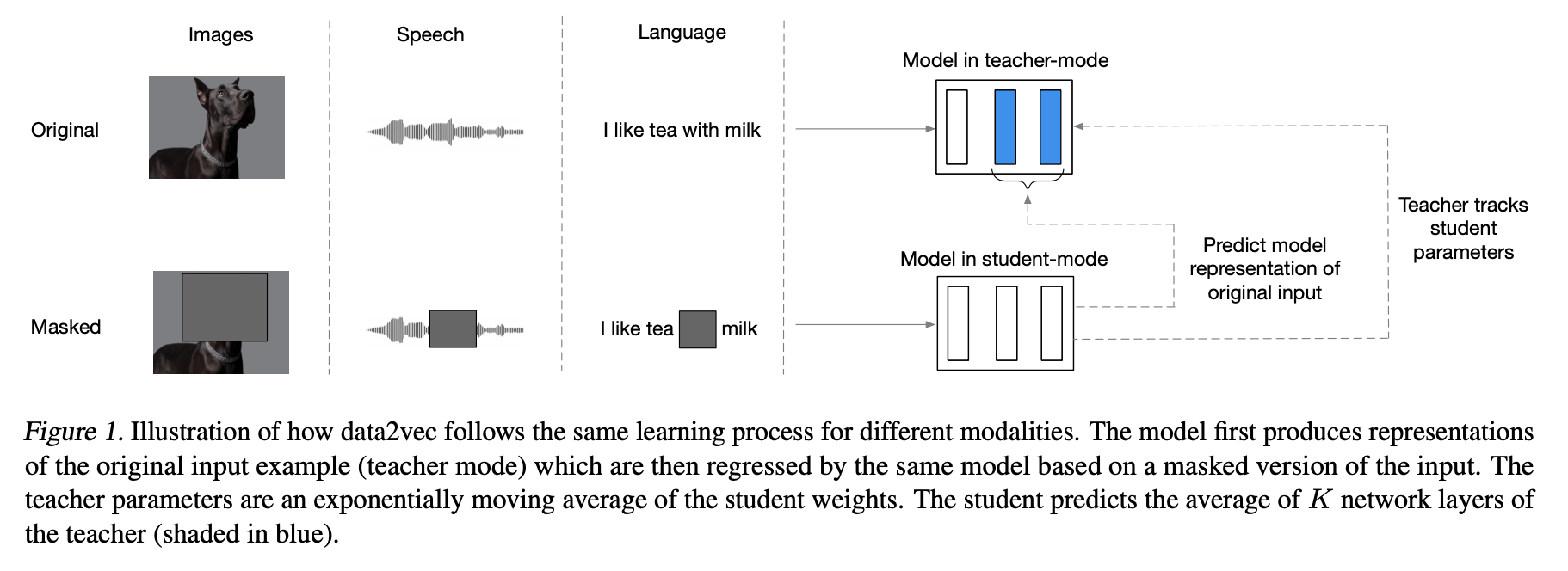
data2vec의 경우 a partial view of the input가 주어지면 전체 full input data의 model representations을 예측하도록 학습시켜진다.
처음에 a masked version of the training sample (model in student mode)을 encode하고 그 후 동일 모델로 unmasked version of the input을 encode해서 training targets을 만든다. 하지만 an exponentially moving average of the model weights으로 paramerize 한다 (model in teacher mode).
☻ Model architecture
Modality-specific encoding을 갖은 standard Transformer architecture을 사용하였다. 즉, 입력의 encoding방법은 modality 에 따라 다르지만, 모델 구조나 학습 방법자체는 통합된 형태를 띄고 있다.
☻ Masking [13]
Input sample이 a sequence of tokens으로 임배딩 된 후에, a learned MASK embedding token으로 바꿈으로써 masking하고 sequence를 transformer 네트워크에 공급한다. 이때 modality에 따라서 다른 masking방법을 고려한다.
CV의 경우, BEiT masking 방법을 사용한다. 이는 image patches를 임의로 masking하는 방법을 사용하는데 인접한 블록을 masking하는 blockwise방법을 사용한다.
Speech의 경우, wave2vec masking 방법을 사용하고, 이때 latent speech representation을 추출하기 위해 cnn 구조를 사용하고 n개의 token을 연속적으로 masking한다.
NLP의 경우, RoBERTa masking 방법을 사용한다. BERT는 한번만 random masking을 하고 모든 epoch에서 동일한 mask를 반복하지만 RoBERTa에서는 매 epoch마다 다른 masking을 수행하는 dynamic masking 방법을 사용한다. 또한 BERT와 달리 다음 문장을 예측하는 방법은 사용하지 않는다.
☻ Trainning targets
An encoding of the masked sample 을 기반으로 original unmasked training sample의 model representations을 예측하기 위하여 모델을 학습시켰다.
✤ Teacher parameterization
Teacher paramter 경우 BYOL에서 제안한 an exponentially moving average (EMA)을 통해 parameterize하는데, 이때 두개의 parameters인 student model weight, 𝝷와 teacher model weight, 𝝙 을 어떻게 학습시키는지가 중요하다.
τ = 1이면 teacher model weight만 사용하고, τ = 0 이면 student model만 사용한다.
본 연구에서는 τ을 학습의 첫 n번의 업데이트 동안 τ0에서 τe 까지 선형적으로 증가하도록 스케줄링하고, 남은 학습 시간동안은 일정한 상수값을 갖게 하였다. 이러한 전략은 모델이 random인 학습 초기에는 teacher가 좀 더 자주 업데이트되고 어느정도 학습이 된 이후, 즉 좋은 parameter을 학습한 이후에는 적게 업데이트 되도록 한 것이다.
✤ Target [3]
보는 바와 같이 student model에는 masked input을 teacher model에는 original input을 사용한다. transformer 자체의 output을 맞추게 되는 형태를 갖고 있으며 teacher model의 아웃풋이 target이 되고, student model의 masked input된 것의 아웃풋이 target을 잘 representation을 잘 따라가도록 loss를 전파한다.
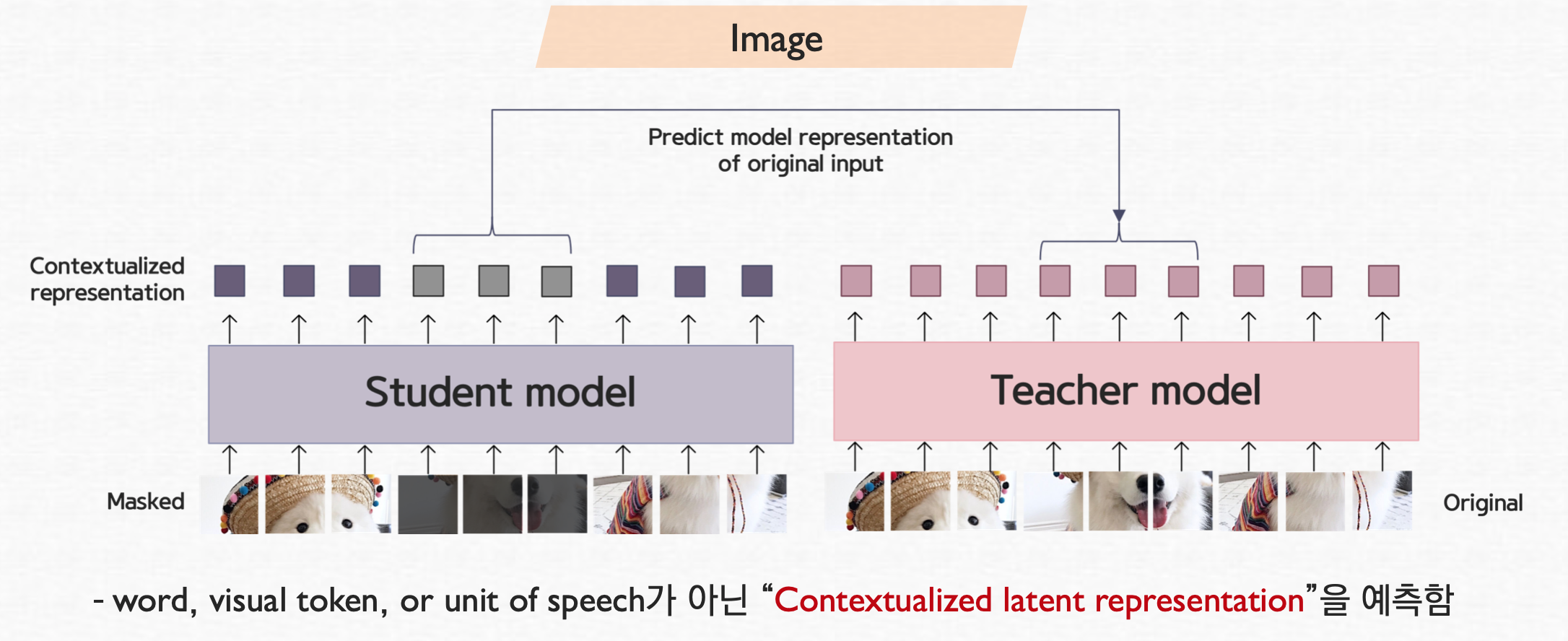
Fig [3]
target 모델 (teacher model)의 경우는 original input이 그대로 들어가며 이 모델을 transformer 구조를 갖고 있으므로 보는 바와 같이 self-attention layers을 이룬다. 근데, 이때 상위 top K layers을 사용해서 target, y를 산출한다. 이때, 각 layer에서 output을 normalization을 하고 이 값들의 평균을 취한다. 이를 통해 성능이 더 높다는 것을 확인 할 수 있었다. speech의 경우 instance norm을 CV와 NLP의 경우 layer norm을 사용하였다.
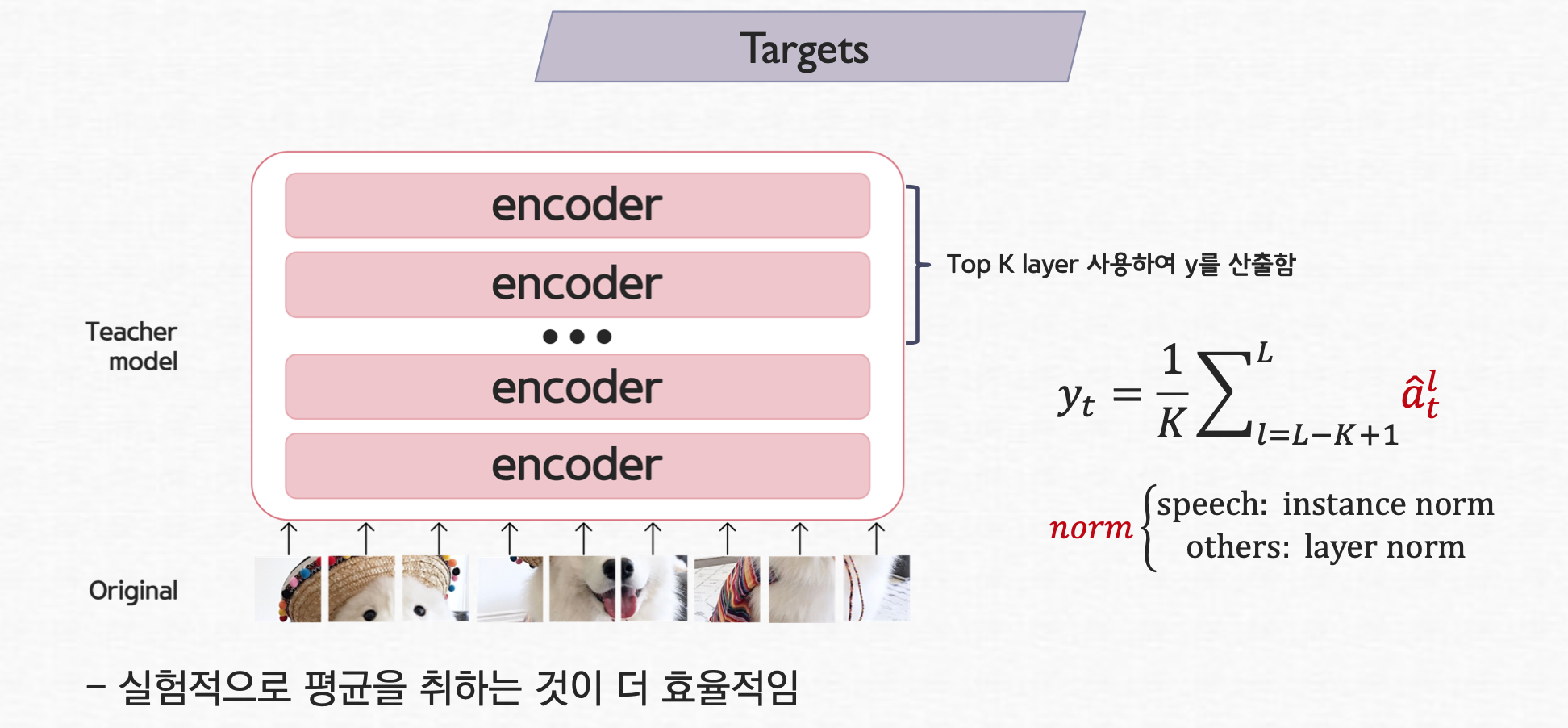
Fig [3]
✤ Objectives
Time step, t에서 teacher model에서 나온 target,yt 과 model predicton (즉, Student의 출력값), ft에 대해서Smooth L1 loss로 regression을 수행한다.
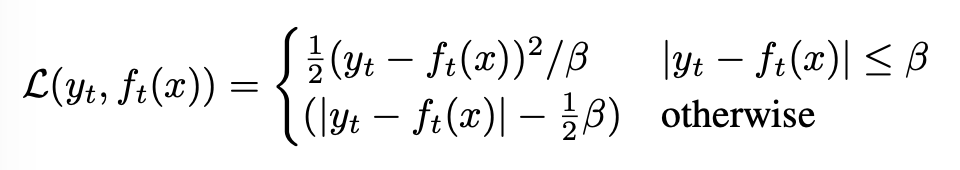
이 losss의 경우 outlier에 덜 민감하다는 이점을 갖고 있지만, β를 잘 튜닝 해야한다.
☺︎ Experimental setup + Results
여기서는 두개의 모델 data2vec Base와 data2vec Large를 고려하였다. 두 모델의 Transformer blocks (L)과 hidden dimension(H)는 12 x 768 혹은 24 x 1024 이다.
각 모달의 hyperparamters, paramter tuning은 논문에서 확인 가능하다.
☻ Computer vision
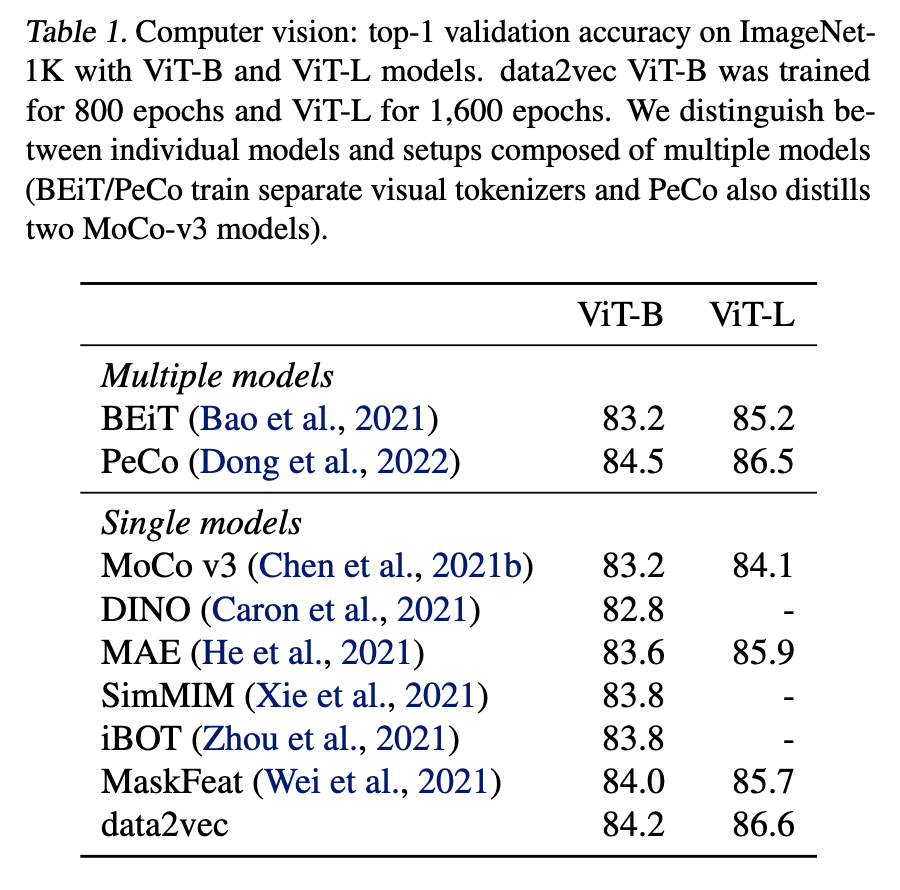
ImageNet-1K training set으로 data2vec를 pretrain하고 동일한 벤치마크의 labeled data사용해서 이미지 분류를 위한 결과 모델을 미세 조정하였다. 아래 표에 나오는 바와 같이 다른 모델에 비하여 더 좋은 성능을 보여준다.
☻ Speech processing
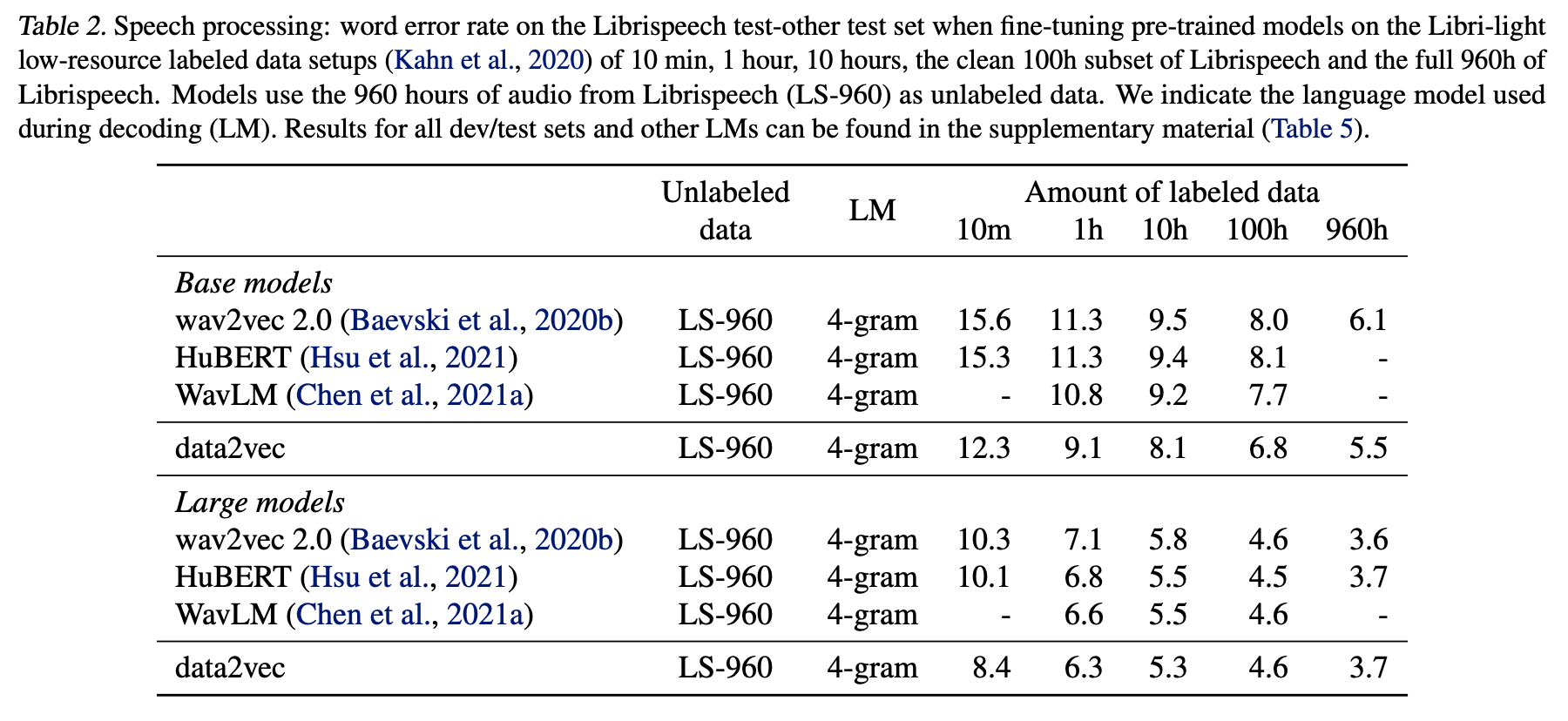
Librispeech (LS-960)에서 얻은 960 hrs 의 speech audio data로 data2vec를 pre-train하였다. 그리고 다른 양의 labeled data를 이용해서 automic speech recognition을 위해서 모델을 fine-tune하였다.
유명한 알고리즘인 wav2vec 2.0 (Baevski et al., 2020b)와 HuBERT (Hsu et al., 2021)와 비교하였다.
☻ Natural anguage processing (NLP)
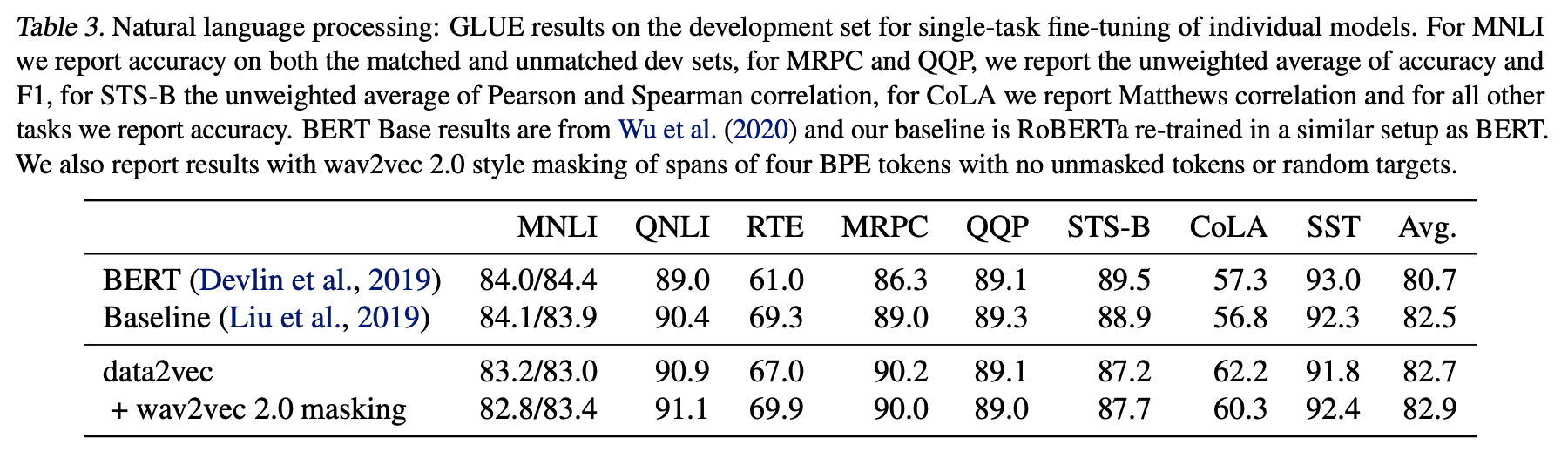
본 연구에서는 BERT와 같은 training set을 적용하였다.
we adopt the same training setup as BERT (Devlin et al., 2019)by pre-training on the Books Corpus (Zhu et al., 2015) and English Wikipedia data over 1M updates and a batch size of 256 sequences. We evaluate on the General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2018) which includes tasks for natural language inference (MNLI, QNLI, RTE), sentence similarity (MRPC, QQP and STS-B), grammaticality (CoLA), and sentiment analysis (SST-2).
☺︎ Discussion
기존 연구와 비교하였을때 본 연구의 특징을 기술하고자 한다.
☻ Modality specific features extractors and masking
- 본 연구의 가장 큰 목적은 다른 modality에 대해서 single learning mechanism을 설계하는 것이다.
- unified learning regime이 있음에도 불구하고 여전히 특정 부분, modality-specific features extractors/masking strategies에서는 modality-specific하다. 즉, 여전히 modality dependent하게 적용해줘야 하는 부분이 존재한다.
- 이러한 예로, speech의 input의 경우는 very high resolution input (16kHz waveform)이 필요한데 비해 NLP의 경우는 lower resolution (in the form of much shorter word sequences)이다. 따라서 modality에 따라 다른 input을 고려해줘야 한다.
☻ Structured and contextualized targets
- 다른 masked prediction 연구들과의 큰 차이점은 contextualized feature를 학습하는 것에 있다.
- NLP의 경우,data2vec은 pre-defined target units에 의존하지 않은 첫번째 연구이다.
Most other work uses either words, sub-words (Radford et al., 2018; Devlin et al., 2019), characters (Tay et al., 2021) or even bytes (Xue et al., 2021). Aside, defining word boundaries is not straightforward for some Asian languages. Contextualized targets enable inte- grating features from the entire sequence into the training target which provides a richer self-supervised task.
☻ Representation collapse
- Self-supervised learning처럼 자기 자신의 targets을 배우는 알고리즘의 흔한 이슈중 하나가 representation collapse이다.
- 이는 모델이 all masked segments에 대해서 매우 유사한 representation을 생성한다.
- 이러한 collapse가 발생하는 시나리오로는
- (1) the learning rate is too large or the learning rate warmup is too short which can often be solved by tuning the respective hyperparameters.
- (2) τ is too low which leads to student model collapse and is then propagated to the teacher. This can be addressed by tuning τ0, τe and τn.
- (3) adjacent targets are very correlated and where longer spans need to be masked, e.g., speech. We address this by promoting variance through normalizing tar- get representations over the sequence or batch (Grill et al., 2020). For models where targets are less correlated, such as vision and NLP, momentum tracking is sufficient.
이러한 collapse의 하나로 가장 많이 거론되는 것이 GAN의 mode collapse가 있다.
Mode collapse란 GAN을 학습시킬때 생성자(Generator)가 다양한 이미지를 만들어내지 못하고 비슷한 이미지만 계속적으로 생성하는 것을 의미한다 [14].
However, if a generator produces an especially plausible output, the generator may learn to produce only that output. In fact, the generator is always trying to find the one output that seems most plausible to the discriminator. If the generator starts producing the same output (or a small set of outputs) over and over again, the discriminator’s best strategy is to learn to always reject that output. But if the next generation of discriminator gets stuck in a local minimum and doesn’t find the best strategy, then it’s too easy for the next generator iteration to find the most plausible output for the current discriminator [15].

Fig [16]
여러 modality에서 general한 방법을 사용한다 했지만, data2vec의 경우도 input encoder와 masking이 modality specific하다는 한계점이 존재한다. 이는 추후 이 과정들도 모두 modality independent 하게 바꾸는 방향으로 나아가야 한다고 생각한다.
☺︎ Extra notion
추가적인 개념에 대해서 다루고자 한다.
☻ Transformer model [17, 18]
트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 “Attention is all you need”에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델이다.
![]()
Fig [18]
이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보여준다. 따라서 최근에는 대표적인 딥 러닝 모델로 손꼽혔던 합성곱과 순환 신경망(CNN과 RNN)을 대체하고 있다. 파운데이션 모델(foundation model)이라고도 불린다.
![]()
Fig [17]
☻ Contextualized Word Representation [19]
Contextualized Word Embedding은 단어를 저차원 (일반적으로 100~500 차원) 공간에서 표현하는 기법으로 기존의 전통적 Word Embedding과는 달리, 같은 단어라도 문맥에 따라 그 표현 방법 (representation)이 바뀔 수 있는 개념의 Embedding이다. NLP에서 많이 사용되는 ELMo, Bert, OpenAI GPT등도 Contextual Word Embedding에 속하는 기법들이다. 또한 이러한 작업을 위해 매우 Deep 한 신경망을 사용한다.
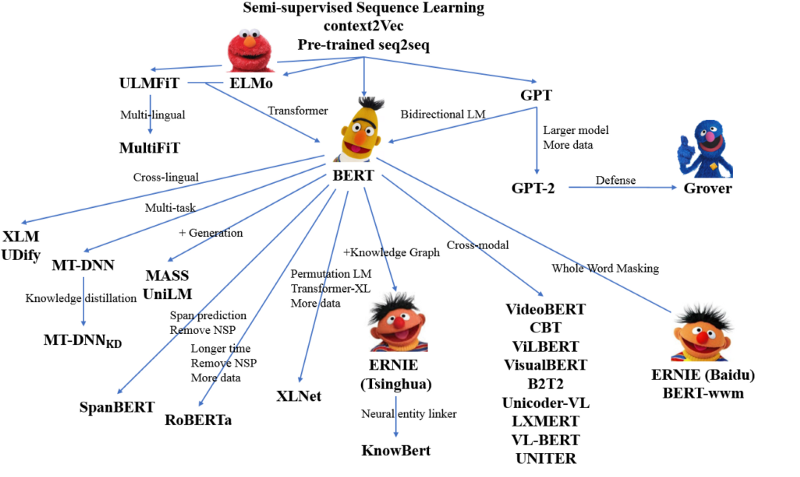
[20]
☻ Reference
- Paper: data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
- Blog: Meta AI
- DSBM: data2vec
- Blog: Data2Vec Review
- wikipedia: self-supervised learning
- Self-supervised learning: The dark matter of intelligence
- Blog: Self-Supervised Representation Learning
- Unsupervised Visual Representation Learning by Context Prediction
- paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- paper: wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
- Multimodality and Language Learning
- Blog: 멀티모달
- blog: 초간단 논문리뷰, data2vec
- blog: GAN model collapse
- blog: GAN, Common problems
- paper: UNROLLED GENERATIVE ADVERSARIAL NETWORKS
- NVIDIA : What Is a Transformer Model?
- 딥 러닝을 이용한 자연어 처리 입문
- blog: Contextualized Word Embedding
- blog: 62 - Contextualized Word Representations
☻ image sources
🌈 Thanks for reading. Hope to see you again :o)
![]()
모두의 연구소에서 진행하는 “함께 콘텐츠를 제작하는 콘텐츠 크리에이터 모임”인 COCRE(코크리) 의 2기 회원으로 제작한 글입니다