Feature Engineering & Preprocessing for NLP
Before we consider diverse models to predict, pretty clean and well-organized ingredients, we are going to call feataures, should be well-prepared. Here, preprocessing and Feature engineering will be covered but these process are limited in NLP field. (Ofc, these concepts could be applied to fields.)
First things first, we should Natural Language Process is. ~~
but it is quite tricky and time consuming process to be read by the computer. ~~ ** 실제 실무에서 확인 할 것 *** 모델 바꾸는 것보다 데이터에서 승부가 나는 것 차라리 토크너나이저같은 것을 바꾸는 것이 중요함 역삼각형이어서 모델을 바꾸는 것보다, 초기를 바꾸는 것이 좋음 버트도 버트의 모델보다 oov줄여서 성능이 좋아지는 것 토크나이저에서 워드 피스를 줄이는 것. 파싱할때 (한국어에서 어간, 어미 쪼갤때)와 같은 토크나이저를 썼을때 성능 올라감 여전히 도메인이 중요. 도메인에서 많이 쓰는 언어가 단어로 할당됨? ~~
Data clearning is actually a part of preprocessing. But, here we consider separately.
☾ Table of contents
☺︎ Data cleaning
- Capitalization/ Lower case
- Expand the Contractions
- Noise Removal
- Remove punctuations
- Other Manual Text Cleaning Tasks
☺︎ Preprocessing
- tokenization
- remove stop words
- stemming
- Part of Speech Tagging (POS tagging)
- Lemmatization
- Other (Optional) Text Preprocessing Techniques
☺︎ Feature extraction
- weighted words - BOW
- countvectorizer
- TF-IDF
☺︎ Embedding
- word2vec -> gensim
- Glove
- FastText
☺︎ Feature Selection
☺︎ What the next step is?
☻ Reference
The pipline of NLP is below
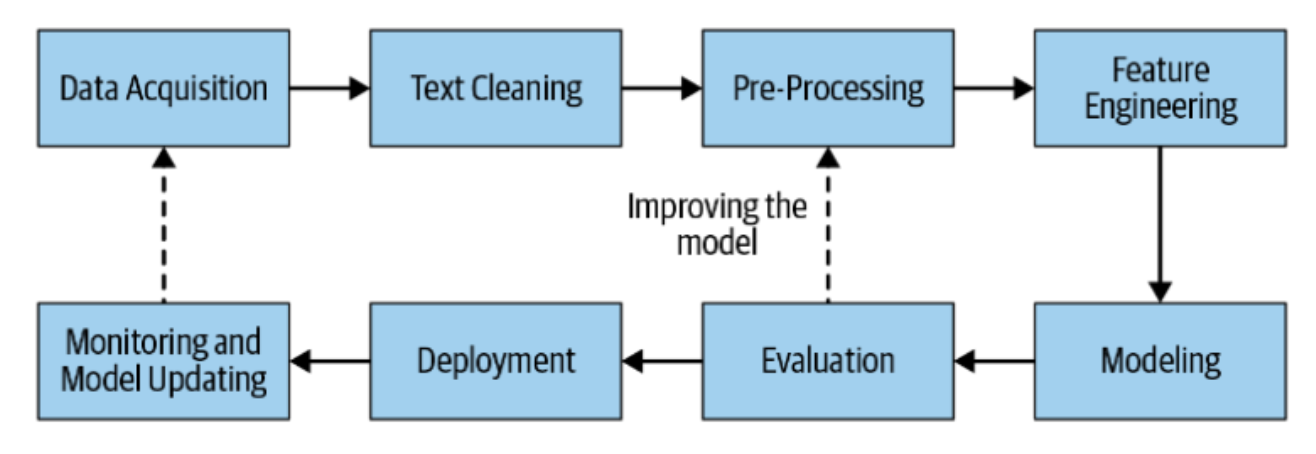
Ref [1]
to undestand datasets and also problems, we should spend 60% (even more) time of the process in preprocessing/feature engineering. Simply
☺︎ Data cleaning [1,2]
basic cleaning such as spelling correction,removing punctuations,removing html tags and emojis etc.*
removing urls removing HTML tags removing Emojis removing punctuations spelling correction
☻ Capitalization/ Lower case [2]
The most common approach in text cleaning is capitalization or lower case due to the diversity of capitalization to form a sentence. This technique will project all words in text and document into the same feature space. However, it would also cause problems with exceptional cases such as the USA or UK, which could be solved by replacing typos, slang, acronyms or informal abbreviations technique. The simple example is below :
Forest fire near La Ronge Sask. Canada -> forest fire near la ronge sask. canada
☻ Expand the Contractions
We use the contractions package to expand the contraction in English such as we’ll -> we will or we shouldn’t’ve -> we should not have.
Y'all can -> you all can
☻ Noise Removal
Text data could include various unnecessary characters or punctuation such as URLs, HTML tags, non-ASCII characters, or other special characters (symbols, emojis, and other graphic characters).
- Remove URLs
- Remove HTML tags
- Remove Non-ASCI
- Remove special characters (Remove special characters : The special characters could be symbols, emojis, and other graphic characters. We use the “Toxic Comment Classification Challenge” dataset as the “Real or Not? NLP with Disaster Tweets” dataset do not have any special charaters in their text.)
☻ Remove punctuations
☻ Other Manual Text Cleaning Tasks
- Replace the Unicode character with equivalent ASCII character (instead of removing)
- Replace the entity references with their actual symbols instead of removing as HTML tags
- Replace the Typos, slang, acronyms or informal abbreviations - depend on different situations or main topics of the NLP such as finance or medical topics.
sample_typos_slang = { "w/e": "whatever", "usagov": "usa government"} # Acronyms sample_acronyms = { "mh370": "malaysia airlines flight 370", "okwx": "oklahoma city weather", "arwx": "arkansas weather"} # Some common abbreviations sample_abbr = { "$" : " dollar ", "€" : " euro ", "4ao" : "for adults only"} - List out all the hashtags/ usernames then replace with equivalent words
- Replace the emoticon/ emoji with equivalant word meaning such as “:)” with “smile”
- Spelling correction : Spelling correction could also be considered an optional preprocessing task as the social media text data is often are typos or mistyped. However, the spelling correction output should be carefully double-checked with the original text input as it could be a mistake.
☺︎ Preprocessing [2]
☻ tokenization
Tokenization is a common technique that split a sentence into tokens, where a token could be characters, words, phrases, symbols, or other meaningful elements. By breaking sentences into smaller chunks, that would help to investigate the words in a sentence and also the subsequent steps in the NLP pipeline, such as stemming.
| Original | Cleaning | Tokens |
|---|---|---|
| Forest fire near La Ronge Sask. Canada | forest fire near la ronge sask canada | [forest, fire, near, la, ronge, sask, canada] |
☻ Remove Stop Words (or/and Frequent words/ Rare words):
Stop words are common words in any language that occur with a high frequency but do not deliver meaningful information for the whole sentence. For example, {“a”, “about”, “above”, “across”, “after”, “afterward”, “again”, …} can be considered as stop words. Traditionally, we could remove all of them in the text preprocessing stage. However, refer to the example from the Natural Language Processing in Action book:
Mark reported to the CEO Suzanne reported as the CEO to the board In your NLP pipeline, you might create 4-grams such as reported to the CEO and reported as the CEO. If you remove the stop words from the 4-grams, both examples would be reduced to “reported CEO”, and you would lack the information about the professional hierarchy. In the first example, Mark could have been an assistant to the CEO, whereas in the second example Suzanne was the CEO reporting to the board. Unfortunately, retaining the stop words within your pipeline creates another problem: it increases the length of the n-grams required to make use of these connections formed by the otherwise meaningless stop words. This issue forces us to retain at least 4-grams if you want to avoid the ambiguity of the human resources example. Designing a filter for stop words depends on your particular application.
In short, removing stop words is a common method in NLP text preprocessing, whereas, it needs to be experimented carefully depending on different situations.
-> 즉, sometimes, stopwords are important to understand sentences. Thus, just removing stop words is not the best option.
nltk에 tokenizer 사전이 존재. 한국어의 경우는 POS tagging 이후에 진행
☻ Stemming : 어간추출, 분석결과가 안좋았을때 하는 경우가 일반적
Stemming is a process of extracting a root word - identifying a common stem among various forms (e.g., singular and plural noun form) of a word, for example, the words “gardening”, “gardener” or “gardens” share the same stem, garden. Stemming uproots suffixes from words to merge words with similar meanings under their standard stem.
There are three major stemming algorithms in use nowadays:
- Porter - PorterStemmer()): This stemming algorithm is an older one. It’s from the 1980s and its main concern is removing the common endings to words so that they can be resolved to a common form. It’s not too complex and development on it is frozen. Typically, it’s a nice starting basic stemmer, but it’s not really advised to use it for any production/complex application. Instead, it has its place in research as a nice, basic stemming algorithm that can guarantee reproducibility. It also is a very gentle stemming algorithm when compared to others.
- Snowball - LancasterStemmer(): This algorithm is also known as the Porter2 stemming algorithm. It is almost universally accepted as better than the Porter stemmer, even being acknowledged as such by the individual who created the Porter stemmer. That being said, it is also more aggressive than the Porter stemmer. A lot of the things added to the Snowball stemmer were because of issues noticed with the Porter stemmer. There is about a 5% difference in the way that Snowball stems versus Porter.
- Lancaster - SnowballStemmer(): Just for fun, the Lancaster stemming algorithm is another algorithm that you can use. This one is the most aggressive stemming algorithm of the bunch. However, if you use the stemmer in NLTK, you can add your own custom rules to this algorithm very easily. It’s a good choice for that. One complaint around this stemming algorithm though is that it sometimes is overly aggressive and can really transform words into strange stems. Just make sure it does what you want it to before you go with this option!
☻ Part of Speech Tagging (POS tagging)
품사를 지정하는 것. 동사/명사/… 문맥적으로 잘 파악할수 있도록 하는 과정. 품사에 따라서 의미가 달라지는 경우가 발생. 한국어의 경우 Part of speech tagging (POS tagging) distinguishes the part of speech (noun, verb, adjective, and etc.) of each word in the text. This is the critical stage for many NLP applications since, by identifying the POS of a word, we can infer its contextual meaning. The NLTK packages offer different POS Tagging algorithms, and in this notebook, we use the combination version of them.
- pos_tag/ DefaultTagger
- UnigramTagger
- BigramTagger
- Could also be a combination of the bigram tagger, unigram tagger, and default tagger (source: https://www.nltk.org/book/ch05.html)
from nltk.corpus import wordnet
from nltk.corpus import brown
wordnet_map = {"N":wordnet.NOUN,
"V":wordnet.VERB,
"J":wordnet.ADJ,
"R":wordnet.ADV
}
☻ Lemmatization:
Lemmatization is the task of determining that two words have the same root, despite their surface differences. The words am, are, and is have the shared lemma be; the words dinner and dinners both have the lemma dinner. Lemmatizing each of these forms to the same lemma will let us find all mentions of words in Russian like Moscow. The lemmatized form of a sentence like He is reading detective stories would thus be He be read detective story.
For example, the “good”, “better” or “best” is lemmatized into good and the verb “gardening” should be lemmatized to “to garden”, while the “garden” and “gardener” are both different lemmas. In this notebook, we will also explore on both lemmatize on without POS-Tagging and POS-Tagging examples
- Lemmatization without POS Tagging
- Lemmatization with POS Tagging
☻ Other (Optional) Text Preprocessing Techniques
- language detection : use the package
polygot - Code mixing and transliteration : This situation should be considered in case of multilingual text such as the mixed up between English and other languages. -> 이런 경우는 여러 언어가 섞여 있는 경우,
☺︎ Text Feature Extraction
transfer Natural language into numerical values the computer understand and read
- weighted words - BOW
- countvectorizer
- TF-IDF
- one-hot encoding
- target encoding : Label of NLP is categorical values, label (text)
Time to time, TF might deliver better results.
☺︎ word embedding
- word2vec -> gensim
- Glove
- FastText
- Bert : transformer 30억개 이상의 단어를 미리 학습시킨후, 본인의 테스크에 따라서 fine tunning을 하면 정확도가 높음.
GloVe for Vecttorization [3] use GloVe pretrained corpus model to represent our words.It is available in 3 varieties
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서 개발한 단어 임베딩 방법론입니다. 앞서 학습하였던 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적으로 나왔고, 실제로도 Word2Vec만큼 뛰어난 성능을 보여줍니다. 현재까지의 연구에 따르면 단정적으로 Word2Vec와 GloVe 중에서 어떤 것이 더 뛰어나다고 말할 수는 없고, 이 두 가지 전부를 사용해보고 성능이 더 좋은 것을 사용하는 것이 바람직합니다.
☺︎ comparison of feature extraction techinique
예로 Bert의 한계가 존재한다면, 이런 문제였을때는 다른 것 사용 할 것 다른 접근법: 각 방법의 약점을 확인하면 좋을 듯 Bert (Transformer)만 사용하다보니, 기존 모델들 RNN A : architecture
☻ Reference
- [Kaggle] https://www.kaggle.com/competitions/nlp-getting-started/data
- [Kaggle, NL_ preprocess] https://www.kaggle.com/code/longtng/nlp-preprocessing-feature-extraction-methods-a-z/notebook
- [wiki doc] https://wikidocs.net/22885
🌺 Thanks for reading. Hope to see you again :o)